For security reasons you may want to store the pipelines to another repository than the one that the code is hosted. Lets say for example that you have your application code located on test-project/repository location but your pipelines are stored on the consoleapp1 repository. Also you want to have continuous integration and deployment for the repository on which the code is hosted, so when code is pushed to repository then the pipeline should trigger which is hosted on ConsoleApp1.
You can do that using the repositories resource of azure devops. You will need to define the repository and also configure trigger for this repository based on your strategy.
The final result would be the pipeline to run when code is commited on the code repository instead of the one that pipelines are hosted.
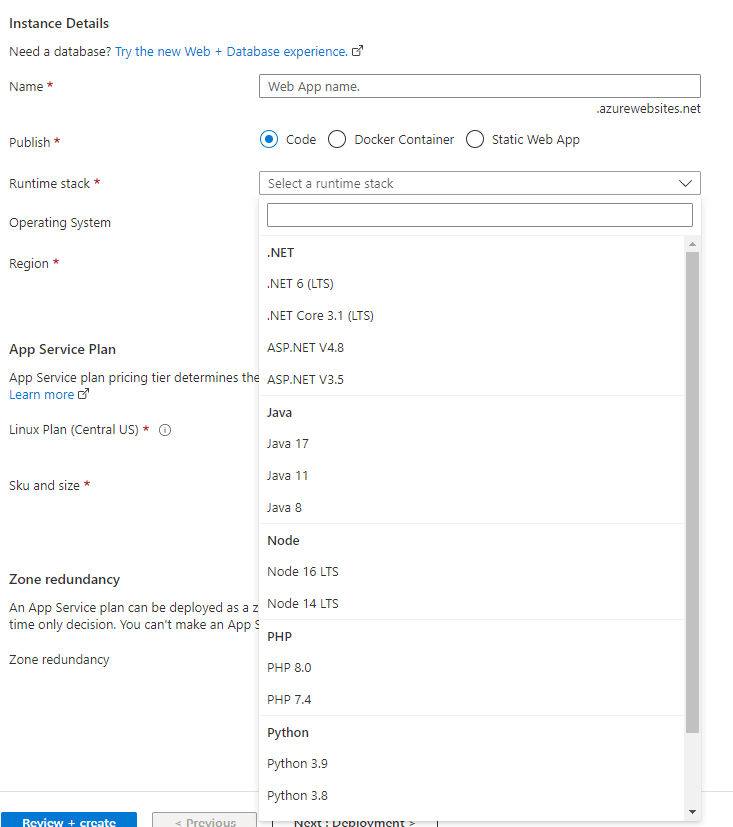
In this article I will demonstrate how one can deploy app service code on Azure through Azure DevOps. App service is a hosting provider for your applications (web app) that can be created with multiple hosting options and application specific settings.
When creating an app service you can choose from many available options like different code frameworks or even container deployments.
For my demo I wanted to deploy an asp .net core web api using .net 6 version hosted on windows app service.
My repository structure is shown below. The app service that I want to deploy is the one located under Front folder.
The pipeline code can be found below:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
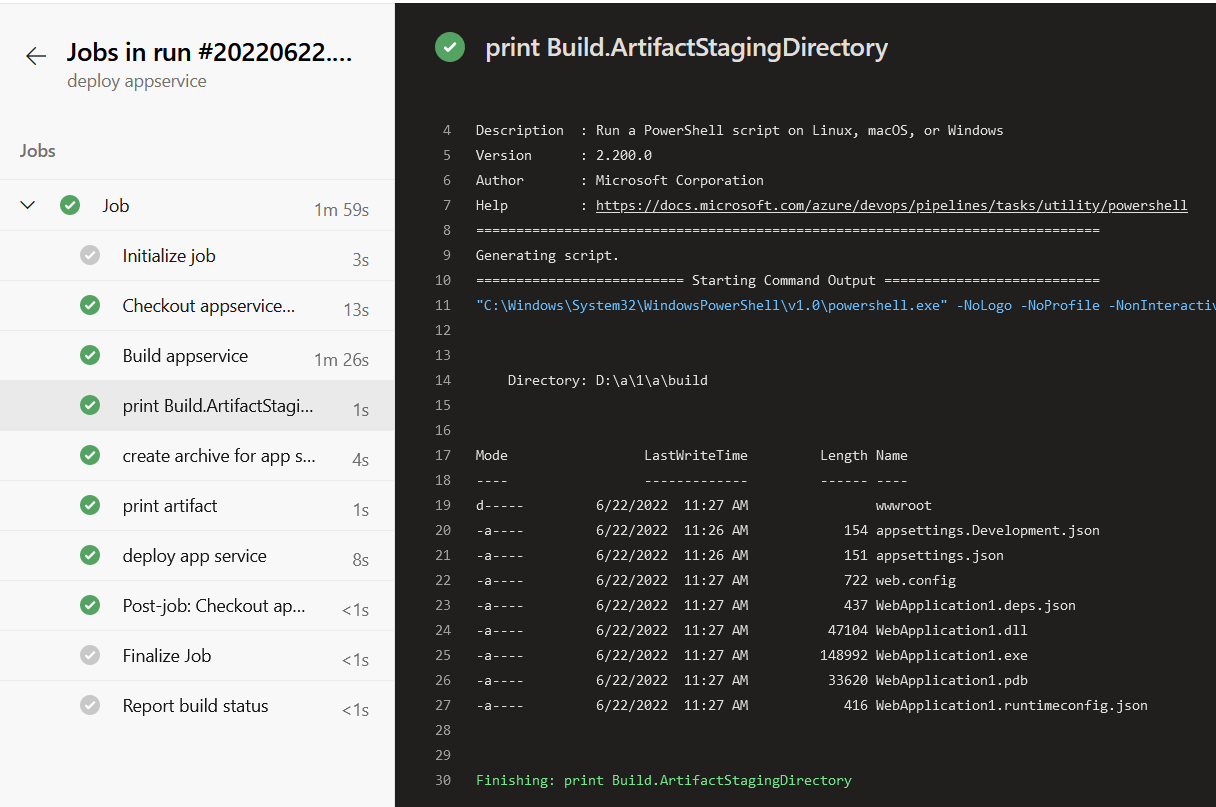
In more detail there are three necessary steps for the deployment.
The first task will build the .NET app using VSbuild task. The build will use as parameters the deployonBuild and the webpublishmethod as filesystem in order to specify the path on which the build output will be stored.
The second task will bundle this build output to a zip file and then the third task will upload this .zip file in the app service using a service connection with the subscription. The two parameters that should be changed are azureSubscription and WebAppName which should be the app service name.
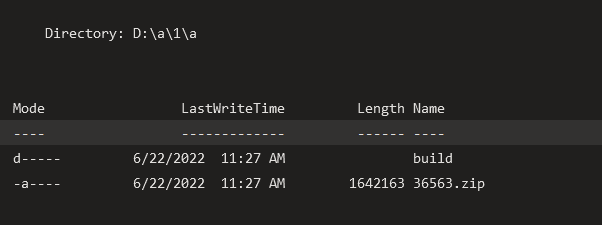
When running the pipeline, a build folder will be created as shown in the below screenshot that will host the build output.
This output will be then zipped to a file that will be uploaded to the app service.
Imagine that you want to enable diagnostic settings for multiple app services on Azure using terraform. The required options can be located under Monitoring tab.
A appropriate rule option should be created to indicate where the logs should be sent.
The available categories can be located below and I will instruct terraform to enable them all.
In order to accomplish that through terraform I used a loop. The depends_on keyword is used because firstly the app services should be created and then the diagnostic settings for them. Create a file like app_diagnostics.tf and place it inside your terraform working directory.
Inside locals.tf I have created a variable that holds the app services ids, the log analytics workspace ID on which the logs will be sent and also the categories which I want to enable on Diagnostics. As shown on the first screenshot all the categories are selected.
As a result the loop will enable for every app service you add on app_service_ids each Diagnostic category placed on log_analytics_log_categories variable.
Most organizations rely on their backup solutions for application faults or data corruptions. However the backup is not frequently tested in order to verify that restore would be successful. In this post I implement a backup testing mechanism.
Lets examine a scenario for an MS SQL database server. The server will output a backup file (.bak) on a storage account based on a retention policy. This backup will be automatically restored on a SQL server through a pipeline and a result will be written as an output. The result can be then reported on the monitoring solution.
The flow is depicted below. An azure devops agent should be installed on the server on which the database will be restored. The pipeline will fetch the backup file from the storage account and store it on a data disk (in my case R:\files). Then sqlcmd command will be used to restore the .bak file and record the result. The backup file is provided by a parameter on the pipeline. Also a service connection should be created with your subscription on which the storage account is located.
Pipeline code:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Azure DevOps agent service is configured to run with a specific account (in my case NT/ Local System). This account should have the appropriate permissions on the SQL server for the restore procedure. The easier way would be to make this account a database sysadmin.
Adding the NT Authority\System on SQL server sysadmins