Azure devops pipelines provide a variety of tools for automated procedures. One mechanism that administrators can build using the YAML structure is an automated rollback mechanism during a deployment.
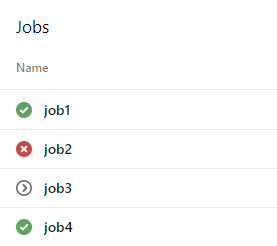
This means that after a deployment you can revert the previous state using your YAML tasks without having to redeploy. Another case would be a broken deployment which can be identified by monitoring tools and then a validation could approve or not the final release. This is exactly depicted in the below image. After releasing a version we have a validation step that requires manual approval from an administrator. If the validation is approved the release will proceed else the rollback will be triggered.

This mechanism is described below with YAML. Release stage includes release, validation and rollback jobs. Release job performs the actual release. Validation will depend on release job and will continue only if is approved. The rollback job will run only if validation failed which means that an administrator canceled the approval.
trigger: none
pr: none
stages:
- stage: releaseStage
jobs:
- deployment: release
displayName: Release
environment:
name: dev
resourceType: VirtualMachine
strategy:
runOnce:
deploy:
steps:
- task: PowerShell@2
displayName: hostname
inputs:
targetType: 'inline'
script: |
deployment script here...
- job: validation
dependsOn: release
pool: server
steps:
- task: ManualValidation@0
inputs:
notifyUsers: 'admin@domain.com'
instructions: 'continue?'
onTimeout: reject
- deployment: rollback
displayName: rollback
dependsOn: validation
condition: failed()
environment:
name: dev
resourceType: VirtualMachine
strategy:
runOnce:
deploy:
steps:
- task: PowerShell@2
displayName: rolling back
inputs:
targetType: 'inline'
script: |
rollback script here..
Write-Host "rollback"
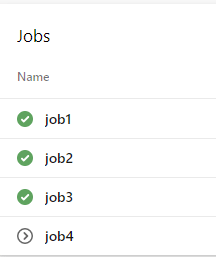
When the release can be verified from the administrator the rollback will be skipped. This is the case when the validation is approved from the user.

Validation task will ask the user for a review.

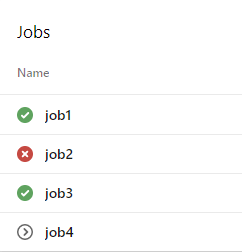
On the other hand if validation is rejected the rollback stage will run.